打假:印度是强奸之国
背景
今天又看到有人吐槽印度是强奸之国,想想上次这事发酵的时候到现在已经快半年了,当时很多很有“知名度”的节目也是吐槽一地。其实我和乙寅当时就很奇怪印度官员既然已经给出了一组明确的数据,为什么没有人去考察相关的数据,而是直接就上来一顿嘲讽。下面让我们来回顾一下这个事件吧。在网上随便都能搜到那个事件的导火索,比如印度官員:性侵案數量其實全球前四低,印度官員:印度強姦案數是世界最低4個國家之一或者来自搜狐的印度女部长:印度属于强奸案最低4个国家之一,大致内容是:
印度婦女及兒童發展部的女部長馬內卡‧甘地(Maneka Gandhi)週一(21日)舉行一場女記者聚會,她在會中表示,印度的強姦案件數量,是世界上最低的4個國家之一,瑞典的案發數第一。
然后网上就出来了各种讨伐文章,在这里列举几个,网上要找的话可谓不一而足。
比如,来自搜狐的: 网友快评:印度强奸案发生率最低 我差点就信了
这个好像还查过资料一样,其中内容不乏:
她说的没有错吧,人家说的强奸率,人家人口基数大啊,一天一万起强奸除以十四亿貌似也只是个小数
替瑞典喊冤“瑞典政府和人民无辜躺枪。
总算知道印度为啥是强奸大国了,因为连那里的女人都不把强奸当回事
其实关于印度是强奸之国的论断很早就有,这里是一个看起来很严肃,做过仔细调研的印度如何沦为"强奸之国"文章,其中不乏煽动性的数字:
数据也证实了这点,根据印度国家犯罪记录局的数据,印度记录在案的强奸案件由1971年的2487起增至2011年的24206起,增长率为873.3%。比较而言,谋杀案件在从1953至2011年的近60年间里的增长率为250%,远不及强奸犯罪率的飙升。 平均下来,在印度每3分钟发生一起针对女性的暴力犯罪,每22分钟就会发生一起强奸案。在印度性犯罪最严重的主要城市新德里,平均每18小时发生一起强奸案,被冠以 “强奸之都”的耻辱称号。
按照一般的理解,作为一个国家的高级官员,说话完全不着边际的可能性是不大的,特别是还列举明确数据的话语。但是如果你真的去查的话,很容易找到的一个条目是中文维基百科的条目,不过不用太多的分析就应该可以发现那个页面的数据是错误的(这个大家自己去分析吧)。所以,我就稍微多检索了一下,很快就能发现联合国药物与犯罪部门公布了性犯罪的相关信息。很容易核对这个表格中的数据和上面文章提供的数据是基本吻合的,应该说也是比较可信的。
分析方法
考虑到不同的国家人口差异比较大,使用每十万人的案件发生数量是比较合理的选择。而像中文维基页面中使用所谓的一个国家每分钟的的案发次数是并不合理的。正是上面说的“人家人口基数大啊,一天一万起强奸除以十四亿貌似也只是个小数”,这话虽然是明显的讽刺,但是确实不加,如果是“一天一千起强奸除以一亿”,不知道这个发言者真的觉得前者比较危险吗?所以我们以下分析的都是每十万人在一年内发生强奸案例的数据。
同时,不同地区之间性犯罪案件的发生件数和登记在案的发生次数也是存在差异的。这一点并不假,特别是在具有“传统美德”的某些国家这个数目更是可能不算小数。但是无疑对于真实的犯案数量和报案数量之间的差异的估计是非常困难的,一个可行的方案可能是认为地理位置和文化相近的区域的这一比例也比较接近。同时,在没有可靠数据的支撑条件下,我们也不应过分夸大这一比例在不同区域的差距。下面让我们开始真正的分析吧!
均值分析
作为标准的分析的第一步,我们先看一下全球的平均水平。几点特征可以注意到,首先每年数据的均值都远过于中位数,其次标准差(SD)对于给定也数据很大,最后整个均值特征量基本是稳定的,没有明显的增长或降低趋势。平均罪案率大概在万分之一。
globalmean <- rape %>%
group_by(Year) %>%
summarise(mean=round(mean(Events,na.rm=T),2),
median=median(Events,na.rm=T),
sd=round(sd(Events,na.rm=T),2))
datatable(globalmean,options = list(pageLength=20))简单的将以上数据绘图,颜色偏棕的年份方差比较大。
p <- ggplot(globalmean,aes(Year,mean,fill=sd))+geom_bar(stat="identity")+
scale_fill_distiller(palette = "BrBG") +
ylab("Mean Value")
p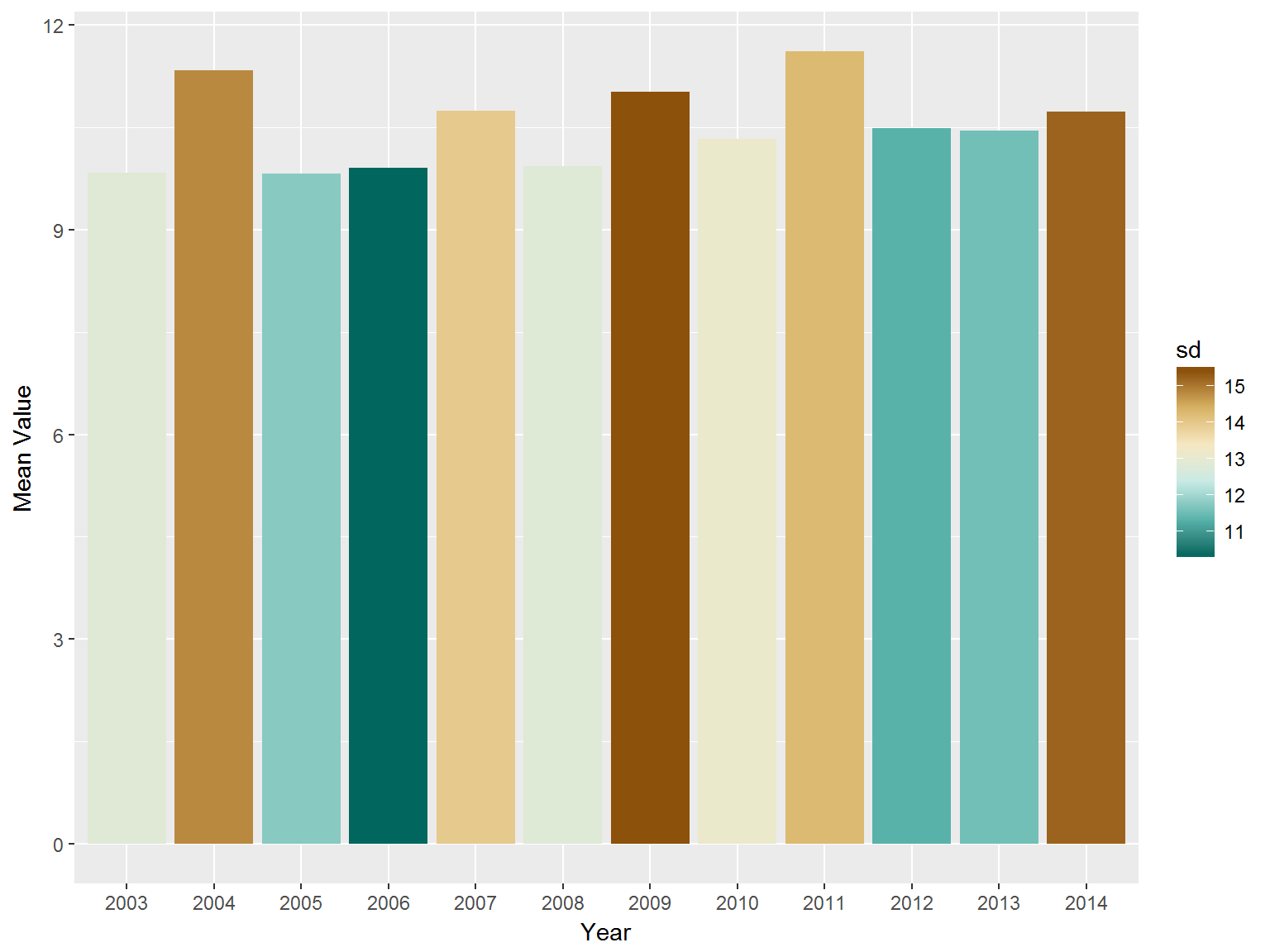
分布分析
第二步,我们考察一下各年的具体分布情况。首先是用boxplot来看一下离群值的情况。可以看到每年都有一些很大的离群值。
p <- ggplot(rape,aes(Year,Events,fill=Year)) +
theme(legend.position = "none") +
scale_fill_brewer(palette = "Paired")
ggplotly(p + geom_boxplot(na.rm = T))boxplot不能看出分布,所以我们使用violinplot来查看一下每年的分布情况:
p2 <- p + geom_violin(na.rm = T)
ggplotly(p2)印度在分布图中的位置
好的,然后如果我们把印度的位置用+标识在上面的图中会是什么位置呢?
pindia <- p2 +
geom_point(data = rape %>% filter(Country=="India"),shape=3,size=5,color="darkblue") + scale_fill_brewer(palette = "Paired")## Scale for 'fill' is already present. Adding another scale for 'fill',
## which will replace the existing scale.ggplotly(pindia)实际上,你需要缩放到10以下,才能看到印度的案件发生率。至少从这个图上来看,来自印度的消息似乎不是毫无根据,而是空穴来风。那么让我们继续分析这个数据。
pindia + ylim(0,10)## Warning: Removed 2 rows containing missing values (geom_point).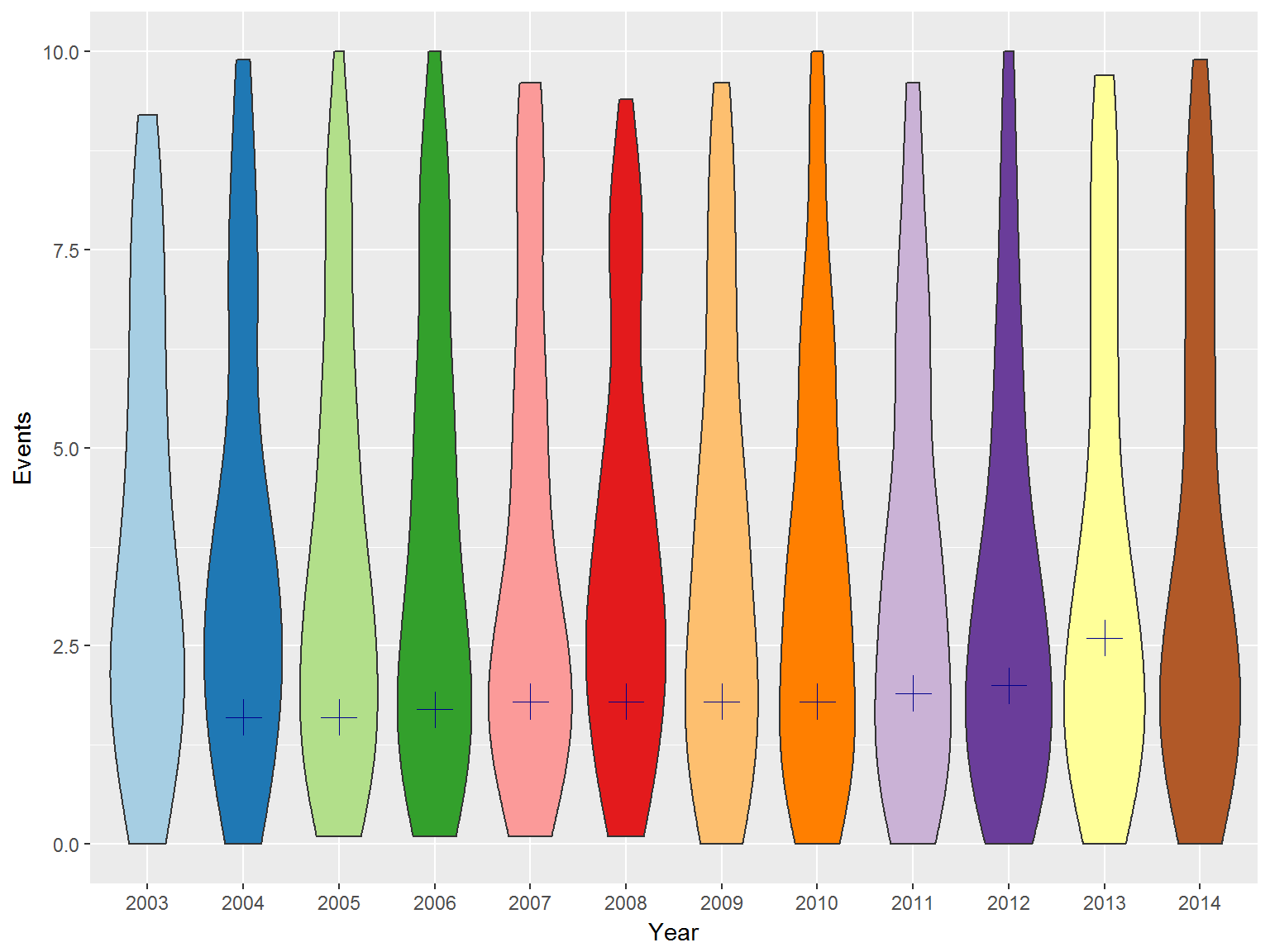
各大洲的情况
将原始数据按照各大洲的情况分组统计可以得到如下的结果。从结果来看,似乎大洋洲是一个令人恐怖的所在。
p <- ggplot(rape,aes(Region, Events, fill = Region)) +
geom_violin(na.rm=T) +
scale_fill_brewer(palette = "Paired")
ggplotly(p)对于数据爱好者,我也提供一下数据吧:
globalmean <- rape %>%
group_by(Region) %>%
summarise(mean=round(mean(Events,na.rm=T),2),
median=median(Events,na.rm=T),
sd=round(sd(Events,na.rm=T),2))
knitr::kable(globalmean)| Region | mean | median | sd |
|---|---|---|---|
| Africa | 10.66 | 2.60 | 22.43 |
| Americas | 19.30 | 18.80 | 12.74 |
| Asia | 3.92 | 2.50 | 4.15 |
| Europe | 9.33 | 5.60 | 10.54 |
| Oceania | 24.31 | 26.25 | 7.87 |
如果我们继续细分分类的话,会出现下面这张不美观的图片。不过,大家可以移动鼠标去查看每个部分代表具体数据。可以看到总体数据来讲,南非区域是鹤立鸡群地高呀!这个大概和平常的新闻媒体传播还是比较吻合的。
orape <- rape
rape$Country <- unlist(lapply(rape$Country, function(x) substr(x,1,10)))
ggplotly(ggplot(rape,aes(`Sub Region`, Events, fill = `Sub Region`)) +
theme(legend.position = "none",
axis.text.x = element_text(vjust = 0.25,angle = 90)) +
geom_violin(na.rm=T) )亚洲地区的数据
好了,我们就不去研究非洲的问题。回来看看亚洲地区的数据吧!这亚洲的国家数量真是很大,大家只能移动鼠标去查看每个数据块对应哪个国家了。几点观察是明显的:
- 作为发达国家,日本的罪案率很低。
- 印度在亚洲国家中也算罪案率不高的。也就是考虑到亚洲地区记录在案的犯罪比例可能偏低,那么在同一地区而言,印度的记录也不算很高。比如附近的泰国罪案率就远高于印度。虽然对于印度及其周边国家的文化并不了解,不过认为印度的罪案记录率又远低于周边地区的话似乎也不是很有道理的假设。
- 邻国蒙古亮了。
p <- ggplot(rape %>%
filter(Region=="Asia"),
aes(Country, Events, fill = Country)) +
theme(legend.position = "none",
axis.text.x = element_text(vjust = 0.25,angle = 90)) +
geom_violin(na.rm=T)
ggplotly(p)欧洲地区的数据
考察欧洲主要是因为之前谣言的对手是欧洲的。可以看到,欧洲里瑞典(Sweden)可谓一枝独秀。
p <- ggplot(rape %>%
filter(Region=="Europe"),
aes(Country, Events, fill = Country)) +
theme(legend.position = "none",
axis.text.x = element_text(vjust = 0.25,angle = 90)) +
geom_violin(na.rm=T)
ggplotly(p)让我们放大到北欧看看,无疑确实瑞典是很高。
p <- ggplot(rape %>%
filter(`Sub Region`=="Northern Europe"),
aes(Country, Events, fill = Country)) +
theme(legend.position = "none",
axis.text.x = element_text(vjust = 0.25,angle = 90)) +
geom_violin(na.rm=T)
ggplotly(p)可以观察到, 北欧的罪案率普遍偏高。这一点确实和欧美文化有关,很大程度上欧美的罪案更大可能性会被记录在案,但是这同是北欧(这个地区的文化好像差异不大),瑞典的这个数据实在是让人比较难堪了。同时,这个基准值大家可以记录下来,到时候可以去数据表格中查看类似文化国家的罪案率怎么样,我就不做分析了。默默的在最后附上了各国的罪案发生均值和中位数,以供大家研究。
最后据最高人民法院的消息,去年中国各级法院审结的拐卖、性侵妇女儿童案合计5335件,照此可以估计大概的罪案率情况,这个交给大家吧。
各国的数据
datatable(orape %>% group_by(Country) %>%
summarise(Mean=round(mean(Events,na.rm=T),2),
Median=round(median(Events,na.rm=T),2),
SD=round(sd(Events,na.rm=T),2)) %>%
arrange(desc(Mean)),filter="top",options = list(pageLength=25))